前几天接到了一个单,话说这需求真有点怪,他给一个一些列网址链接,拿到链接的html源码保存到本地存为html格式,打开其文件内容和图片要求原网站一致,我测试了几个网址,都是静态的,完全没问题,后面多了后发现有动态加载请求的,额,无奈只能用selenium来弄了,代码如下
from selenium import webdriver
import re
from w3lib import html
num = 0
with open('url.txt','r') as fi:
txt = [ii.replace('\n','').replace('\r','') for ii in fi.readlines()]
def f(url):
# proxy = '代理ip'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
#
chrome_options.add_argument('--disable-gpu')
we_b = webdriver.Chrome('chromedriver.exe',options=chrome_options)
script = ''' Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) '''
we_b.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": script})
we_b.get(url)
we_b.implicitly_wait(5)
return we_b
for url in txt:
num += 1
we_b = f(url)
title = we_b.find_element_by_xpath('//h1').text
print(title)
text = we_b.page_source
with open('{}.html'.format(title),'w',encoding='utf-8') as file:
file.write(text)
we_b.close()
效果很好,但是打开本地的html加载却要很久,我打开html查看源码发现要加载好多链接,请求很多其他的网站,如图所示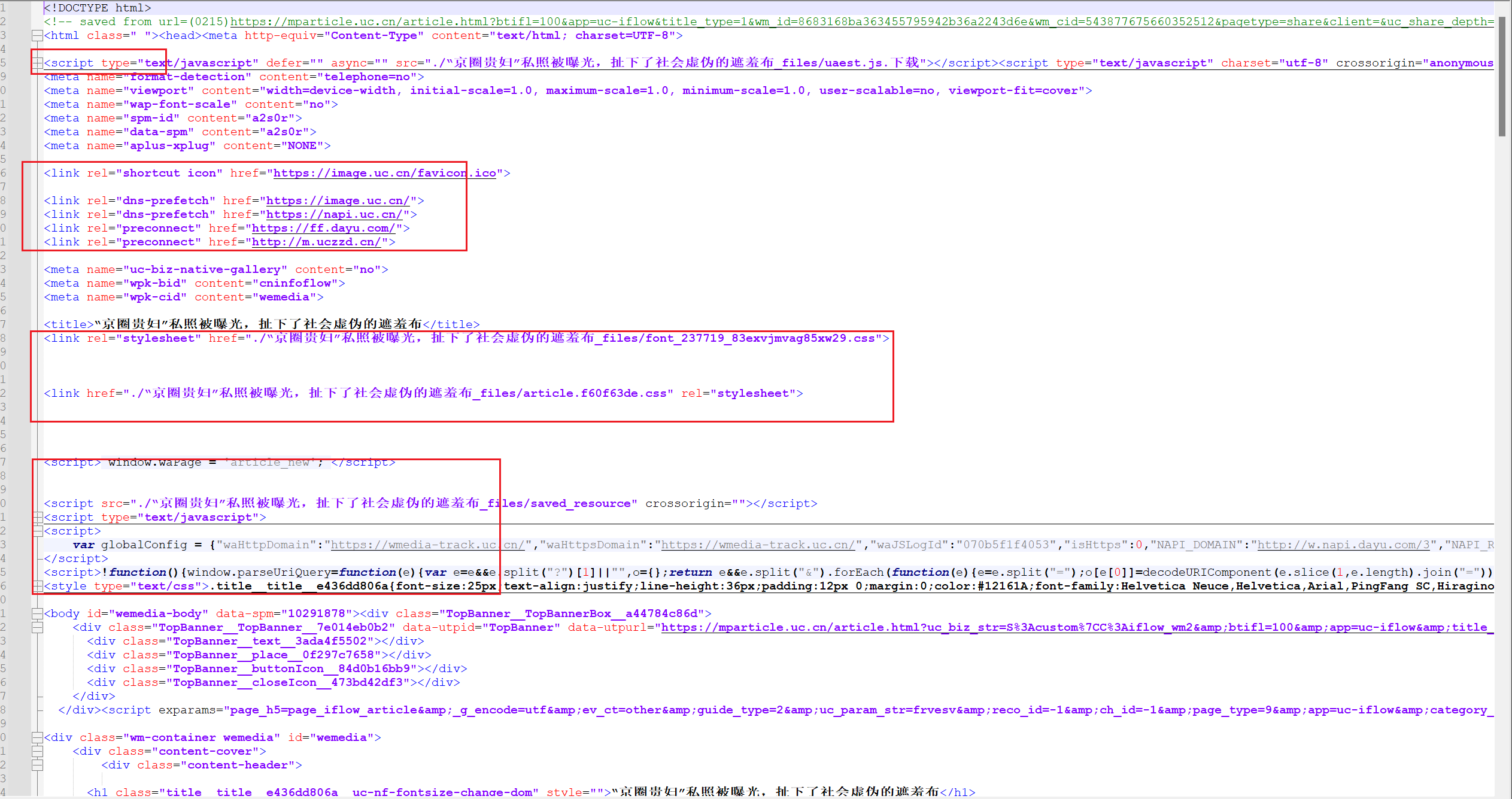
大量请求资源导致打开异常缓慢,因此决定去除link,script等标签,开始打算用正则表达式来判断,发现script标签众多符号非常复杂,甚至有些字符和正则表达式字符大量冲突,因此难度较大,后面发现python提供了第三方库w3lib,可以去除特定标签,完整代码如下所示
from selenium import webdriver
import re
from w3lib import html
num = 0
with open('url.txt','r') as fi:
txt = [ii.replace('\n','').replace('\r','') for ii in fi.readlines()]
def f(url):
# proxy = '代理ip'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
#
chrome_options.add_argument('--disable-gpu')
we_b = webdriver.Chrome('chromedriver.exe',options=chrome_options)
script = ''' Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) '''
we_b.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": script})
we_b.get(url)
we_b.implicitly_wait(5)
return we_b
for url in txt:
num += 1
we_b = f(url)
title = we_b.find_element_by_xpath('//h1').text
print(title)
text = we_b.page_source
text = html.remove_tags_with_content(text,which_ones=("script","style","head",'h1'))
with open('{}.html'.format(title),'w',encoding='utf-8') as file:
file.write(text)
we_b.close()
print('第{}页采集完毕'.format(num))
print('\n')
完美解决
如果上述代码帮助您很多,可以打赏下以减少服务器的开支吗,万分感谢!


 赣公网安备 36092402000079号
赣公网安备 36092402000079号
点击此处登录后即可评论